Soy estudiante de ingeniería electrónica de la Universidad Simón Bolívar de Venezuela (USB), hace unos meses me encontraba cursando la materia “Arquitectura del computador 2” donde se nos estuvo evaluando la elaboración de programas en lenguaje “Assembler”. Una de nuestras evaluaciones fue estudiar el funcionamiento de la memoria cache a través del simulador RARS.
Objetivos:
Estudiar el funcionamiento de una caché.
Se nos hizo entrega de un archivo llamado P1.c el cual suma los elementos de un arreglo de cierta manera, Se nos pidió reescribir el programa en ensamblador RISC-V y ejecutarlo en el simulador RARS, con configurando la cache de datos con: Tamaño de la cache en bytes = 128, tamaño del bloque = 4 y numero de vías =2. Para luego responder las siguientes preguntas:
1) ¿Cómo se llama la configuración de memoria caché asignada?
● Suponga que el tiempo de acceso a la memoria, en caso de fallos, son la suma de los últimos dígitos de sus carnets, y que la caché de datos accede a la memoria una palabra a la vez. Calcule el tiempo total de penalización por cada fallo al ejecutar su programa. Queda a su consideración el valor del tamaño del arreglo.
● Ejecute su programa para 10 diferentes tamaños del arreglo a sumar, y llene la tabla
2) Determine y explique para cual tamaño del arreglo funciona mejor el código, y cuál es la tendencia del rendimiento de la caché a medida que se aumenta el tamaño del arreglo.
Implementación y desarrollo:
El código en “assembler”:
Primero se establece el tamaño del arreglo en la sección de data. Este tamaño se determina multiplicando el tamaño del arreglo que se quiere por 4 ya que cada espacio de memoria están separados 4 bytes. Luego se carga esa dirección en el registro a0. En el código hay dos “loops”, primero el “loop” que llena el arreglo y el segundo es el que comienza la suma. Para ambos casos se usa “bltu” para saltar al “label” que suma y que rellena.

Este “loop” es para rellenar el arreglo con números. El registro a2 contiene el tamaño del arreglo.

Aquí se encuentra el “loop” que ejecuta las sumas. Una vez que el “offset” (registro a4) llegue a 1, se sale del “loop” de suma y termina la ejecución del código. Del “label” suma se puede ver que se cargan los valores de arreglo(i) y arreglo(i + “offset”) en los registros a5 y a6 respectivamente. Luego el resultado de la suma se guarda en el registro a7 y se almacena en la posición de arreglo deseada. Vemos que para acceder a diferentes posiciones del arreglo tenemos que sumar por múltiplos de 4 la dirección en a0.
También existen 3 “labels” de parámetros para reiniciar los valores necesarios para que no ocurran errores en las diferentes posiciones de memoria del arreglo y de algunos registros que hacen que el código se ejecute correctamente.
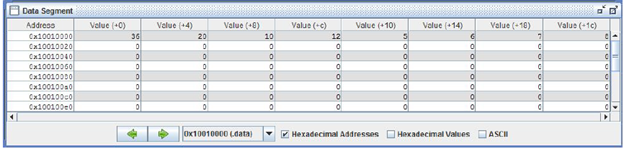
Para un arreglo de 8 espacios, este sería el resultado final, el cual es igual al ejemplo que se demostró en el enunciado de la actividad. A partir de aquí, se determinan los resultados de otros arreglos cambiando el tamaño de espacio en la memoria y el registro a2 el cual es el que tiene el tamaño del arreglo.
De acuerdo a las diversas configuraciones tabuladas, se trabajó con una memoria caché de 128 bytes. Cada bloque tenía 4 bytes de tamaño y 2 vías de acceso. Este tipo de memoria se conoce como caché asociativo por conjunto de 2 vías.
Suponiendo 1 ciclo de bus para transferencia de dirección, 19 por acceso a memoria (suma de últimos dígitos de carnets) y 1 por transferencia de datos en caso de fallos.
Sea cada bloque de 2 palabras y que la caché accede a la memoria una palabra por vez. La penalización por fallo resulta:
Penalización por fallo = 1 + 2x19 + 2x1 = 41 ciclos por fallo.
De acuerdo a la cantidad de fallos obtenida, la penalización total de la ejecución del programa para un arreglo de tamaño 8 es:
Penalización total: 41 ciclos por fallo x 2 fallos = 82 ciclos
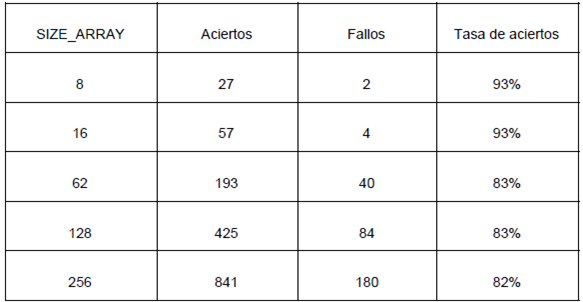
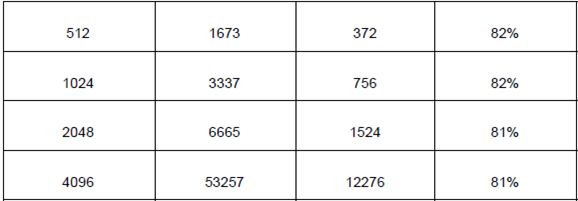
El código funciona mejor para los arreglos de tamaño pequeño, 8 y 16. A medida que el tamaño del arreglo aumenta, el caché empeora su rendimiento hasta llegar a un punto de poca variación entre 83 y 81%.
Esto es debido a la configuración de la caché implementada. Esto hace suponer que mientras menor sea el arreglo, la eficiencia mejore, además el acceso de 2 vías.
Al aumentar el tamaño del arreglo disminuye la eficiencia por penalizaciones en sobre escritura o actualizaciones que afectan el desempeño de la las ejecuciones hasta llegar a mantenerse la eficiencia constante a partir de un tamaño del arreglo de 1024.
Referencias:
Terrones Angel, archivo “P1.c”, entregado en noviembre de 2019