What is it?
Checkpoint is a configuration option where you can specify id of block that has to match when node is about to process it. If block does not match given id, the node should stop. For blocks that are older than last specified checkpoint, a lot of validation checks are not performed, which saves synchronization time. The idea is that when you trust specific witness, you can add checkpoint with block they produced and skip normal validation of blocks up to selected block, because those checks were done by the witness you trust. It is particularly useful when you are setting another node in different server location, where you don't have block log - you can read recent block from the node you have (which performed all the checks), pass that block's id as a checkpoint to configuration of new node, and run sync as an alternative to copying block log and running replay. You can specify many checkpoints (each will be enforced), but the one with highest block number is the most important, since up to that point the validation checks are reduced.
Checkpoint is an old but cryptic feature of Hive node. It didn't even have any tests. When I picked the task of optimizing it, I had to look through code to see what it is supposed to do and how to use it. It didn't do any sanity checks, f.e. if you copy-paste checkpoint to make new, but then you only overwrite id part, number from id and from checkpoint specification won't match - a mistake that is very easy to do and also very easy to prevent. Previously you'd only learn about it when your node synced to such incorrect checkpoint and failed. Also checkpoints were silent - there was only information about existence of checkpoints at the start and when final one was passed. Now each checkpoint leaves a message in log when it is reached (look for lines with test_checkpoint).
For the mainnet testing I've used following checkpoint specification:
checkpoint = [20000000,01312d0047be2e999509f9d7a84132e434d2e8bf]
checkpoint = [40000000,02625a000d8be8b1085b94d25e0c20daf1e9be56]
checkpoint = [60000000,039387005ffd5040dee61d37f5ddf09fefdc8b52]
checkpoint = [80000000,04c4b40015f1b274e95227f6d3bcc1a9bbec8708]
checkpoint = [93000000,058b114080bbaa6ae8b808953ab22a36c2c8c713]
Those lines are part of config.ini.
The whole topic started with discussion under one of @gtg posts.
To be honest it smells like a bug (or more optimistically - as an optimization opportunity).
Dan correctly pointed to undo sessions as potential bottleneck...
Probably we should modify the code dealing with checkpoints to skip undo logic up to the checkpoint.
...but I was sceptical at first. Nevertheless issue was created to check it.
Source pixiv

What changed?
Just as Dan suggested, when incoming block is older than last checkpoint, node no longer creates undo session for it. It also means that such block immediately becomes irreversible. The positive is that it gives massive speedup, because normally every chain object, that is modified during processing of blocks, creates its copy inside undo session. By skipping undo we are not creating any of those copies, nor touch memory that would be needed to hold them. There is a tradeoff though - in case the node somehow gets block that is invalid, it won't be able to recover, so it will stop with broken state. Same if it gets blocks from different fork - it won't be able to switch to main fork. I've never observed any forks during synchronization, but you never know (out of order blocks, yes, but still from main fork, so they are processed properly eventually).
Results
I've run multiple synchronizations and replays up to 93M block (with --exit-at-block 93000000) on the same computer to be able to compare run times. Here are the results from fastest to slowest:
- 22 hours 15 minutes 7 seconds - replay
- 23 hours 20 minutes 45 seconds - synchronization with optimized checkpoints (no undo sessions)
- 35 hours 12 minutes 7 seconds - synchronization with checkpoints prior to optimizations (with undo sessions)
- 38 hours 50 minutes 31 seconds - replay with
--validate-during-replay - 42 hours 42 minutes 36 seconds - synchronization without checkpoints
As expected replay is the fastest and synchronization without checkpoints is the slowest. Replay is the best option if you have your own block log already where you want to start a node from zero. However if you don't have block log at the location, you have to add time necessary to upload it there. Even worse if you have block log not from your own node, but taken from someone else. You should validate its content, but as you can see from results, validation comes at a massive cost.
By the way, checkpoints used to not work during replay, but I've fixed it, so now if you already have block log that you might not want to trust, you can substitute validation with use of checkpoints (not truly the same thing, but considering the cost of full validation...).
The interesting part is synchronization with checkpoints, that is, subject of optimization. In case you don't have a block log where you want to start new node, it used to be so-so option - more convenient than manually downloading block log first for replay, but significantly slower. Still it was actually pretty good option for cases where you don't have much disk space, so you couldn't download full block log for replay anyway (with synchronization you can use pruned block log - technically you could replay in such case, but that would entail a lot of node restarts and manual swapping of block log parts). New optimized version of checkpoints is marginally slower than replay, significant portion of the difference comes from parts when node is network constrained (blocks are processed faster than p2p can download them).
Being network constrained depends on the network :o) You can easily see
how it is in your case by looking through log. Main writer loop has two layers. The outer one tries to report use statistics every 30 seconds. The messages are like the following:waiting for work: 60.82%, waiting for locks: 0.09%, processing transactions: 0.00%, processing blocks: 38.68%, unknown: 0.41%. However during massive sync inner loop won't break as long as there are blocks to process. Therefore you won't have above messages in log when node is CPU constrained. Even if node does catch up with incoming blocks, as long asprocessing blocksis near 100%, it is all good.
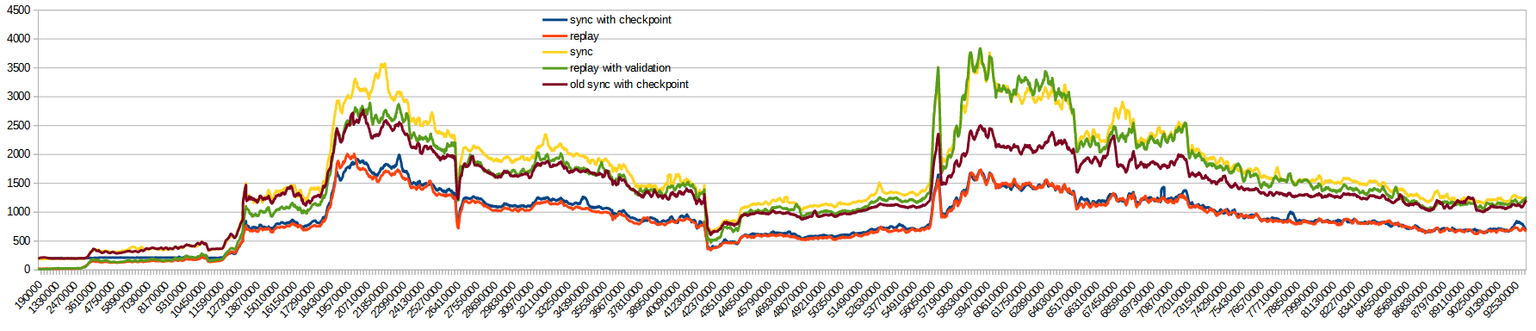
As you can see, during first 3M blocks both replays are significantly faster than syncs, because blocks are almost empty. Later up to 13M they are still better, although replay with validation becomes slower as blocks are more full, while new sync with checkpoints starts to run hand in hand with replay.
The data for the chart is a rolling average of 200k blocks every 10k blocks (without averaging the chart was too jaggy). Y-axis is in microseconds per block.
I'm not sure when the change is going to become part of official release, but as it does not require hardfork, it will be there sooner rather than later. Related merge request !1498 is already merged into develop.
It's nice that sync with checkpoints became viable option, but more exciting changes are coming. In fact three big optimization features from my dream list are already in the works, one even reached review stage. So stay tuned :o)
Congratulations @andablackwidow! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 5000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPActually good.
Greetings @mahdiyari
I have created a high token tracker signal and market analysis website.
My New Hive Token Analysis Website – Live Data & Signals! Complete Guide How to build Also provide source code.